약 3주(22.12.27-23.01.18) 동안 진행되었던 제4회 AI Bookathon 대회 참여 후기를 남기고자 합니다.
"담대한(Daring)"이라는 주제어와 관련된 2만자의 수필을 AI 모델을 통해 생성하는 과정이었습니다.
정말 많은 것을 배우고 느낄 수 있었던 대회였고, 스스로에게 큰 동기부여가 될 수 있었던 경험이었습니다.
함께 결과물을 만들면서 많은 것을 배울 수 있게 해주신 팀원 분(@cosmoquester)께 감사하다는 말을 전해드리고 싶습니다. 자세한 코드는 이 곳에서 보실 수 있습니다.
길었던 여정만큼 긴 후기, 지금 시작합니다.
목차
1. 참여 신청
2. 예선
3. 본선 준비
4. 본선
5. 느낀 점
1. 참여 신청
AI Bookathon 대회는 AI x BOOK + HACKATHON이라는 의미로, 작품 기획, AI 활용, 글쓰기 등을 담당하는 3명 이상의 인원이 팀을 구성하여, 아이디어 도출, 데이터 수집, 머신 러닝, AI 글쓰기 및 문장 다듬기를 통해 한 편의 문학작품을 완성하는 대회였습니다.

저는 평소 글쓰기와 소설쓰는 것에 많은 관심을 가지고 있었기에 이 대회를 1년 전부터 이미 알고 있었습니다. 그래서 이번에는 꼭 참여를 해봐야지,라는 생각을 하였고, 총 3명으로 팀을 이뤄 참가하게 되었습니다.
이렇게 우여곡절 끝에 만난 팀원분들이었지만, 정말 좋은 팀을 만날 수 있었기에 지금 생각해도 운이 따랐다는 생각이 듭니다.
2. 예선

팀이 구성되자마자 진행된 예선은 2일 동안에 걸친 특강과, 이후 대회 측에서 제공한 문제를 풀고 답안을 제출하는 형식이었습니다. 저번 통계데이터 분석 대회 때 협업 툴로 노션(Notion)을 사용한 경험이 있었기에, 이번 대회에도 예선 페이지를 포함하여 전반적인 과정에 대해 노션 페이지를 작성하여 관리했습니다.
저희는 각자 문제에 대한 답안을 작성한 후에 ZOOM으로 모여 답안을 최종적으로 확정하고 답안을 제출하였고, 본격적인 대회 준비는 본선이 확정되고 난 뒤에 진행하였습니다.
3. 본선 준비

본선이 확정되자마자 본격적으로 노션 페이지를 만들어서 도움이 될 만한 정보들과 앞으로의 일정 등 각종 필요사항들을 정리하였습니다. 제가 많은 도움을 받았던건 역시나 기존에 참가하셨던 분들의 후기였습니다. 덕분에 전체적인 흐름에 대해 파악할 수 있었고, 어떤 식으로 진행해야 할지 알 수 있었습니다.
또한, 캘린더를 보면 알 수 있듯이, 무박 2일간의 북커톤 본선 전에 미리 가능한 모든 준비를 해두려고 노력했습니다. 주로 비대면 회의로 진행하였으나 본선 전에 대면 회의를 1번 진행하였는데, 확실히 미리 얼굴을 익혀놓으니 본선 때 더 마음이 잘 맞을 수 있었던 것 같습니다. 대면 회의 때는 미리 기출 단어인 "함께", "길", "만약"에 대해서 글을 생성해보며 어떤 식으로 글을 생성하면 좋을 지를 논의하였습니다.(글 생성과 관련된 내용은 4. 본선의 내용에 적어두었습니다.)
a. 데이터 수집
그 외에 추가로 정보들을 수집한 후 저희는 본격적으로 각자 어떤 데이터를 수집하면 좋을 지 탐색하고, 여건이 되는 대로 각자 데이터 수집 및 크롤링을 진행하였습니다. 이 대회는 수필을 생성하는 대회인 만큼, 주로 수필 데이터 위주로 수집을 하긴 했으나 소설과 시와 같은 데이터들도 염두에 두었습니다. 다만, 실제 학습에는 사용하지 않았습니다.
최종적으로 저희가 사용한 주요 데이터는 다음과 같습니다.
- 브런치 글 "감성에세이" 20만건
- 신춘문예 수상작
- 재미수필문학가협회 수필
- 브런치북 8천건
=> 약 800MB가 넘는 양의 데이터
이 외에도 다양한 곳에서의 데이터를 염두에 두었으나(모두의 말뭉치, 글틴 문학광장, AI hub 낭송/낭독 음성데이터, 백일장 수상작 등) 이미 브런치 글 만으로도 데이터양이 충분하다고 판단하였기에 추가적인 수집은 진행하지 않았습니다.
b. 데이터 전처리

수집된 데이터에서 글 흐름과 관련된 부분은 처리하지 않았고, 주소나 글에 필요없는 요소들, 날짜와 띄어쓰기 같은 것들을 전처리를 통해 제거하였습니다. 그 외에는 모델 학습을 진행하면서 눈에 띄는 문제가 발생한다면 처리하는 것으로 논의한 후 모델 학습을 준비하였습니다.
다른 팀의 경우 이 글에서 소개하고 있는 KLUE에서 사용한 전처리 방법을 사용한 사례들이 제법 보였습니다.
c. 모델 선정
데이터가 준비되었으니, 이제 어떤 사전 학습 모델을 사용하여 에세이를 생성할 것인가를 선택해야 했습니다. 대회 당시(23년 1월)까지 공개되어 있던 모델의 선택지는 크게 4가지였습니다.
- SKT KoGPT2 125M
- SKT Ko-GPT-Trinity 1.2B
- EleutherAI/ployglot-ko 1.3B, 3.8B, 5.8B
- Kakaobrain/KoGPT 6B
저희 팀은 미리 GPU 서버를 통해 어떤 모델이 더 적합할지 테스트를 해볼 기회가 있었습니다. 따라서 T4의 16GB에서도 학습시킬 수 있을만한 모델을 선별해보았을 때, KoGPT(6B)의 경우 가장 규모가 크고 성능도 좋을 것이라 기대되지만, 서버의 크기 상으로 제대로 활용하기 어렵다는 판단하에, 1) SKT KoGPT2 125M, 2) SKT Ko-GPT-Trinity 1.2B, 3) EleutherAI/ployglot-ko 1.3B을 각각 학습시켜 보았습니다.(다만, 본선 발표 때에 KoGPT 6B 모델을 사용한 팀이 1팀 있었으니, 테스트 해보는 것도 추천드립니다.)
큰 모델을 16GB라는 메모리에 올려서 학습시키기 위해서 다양한 전략을 사용할 수 있었는데, 저희 팀에서 선택한 방법은 다음과 같습니다.
- Floating Point 16Bit 사용
- Deepspeed stage2 offloading 적용
- Batchsize를 확보하기 위한 gradient accumulation 적용
다른 팀의 발표를 들었을 때 이 외에 다양한 노력도 접할 수 있었습니다.(batchsize 줄이기, layer freeze, Gradient Checkpointing 등)
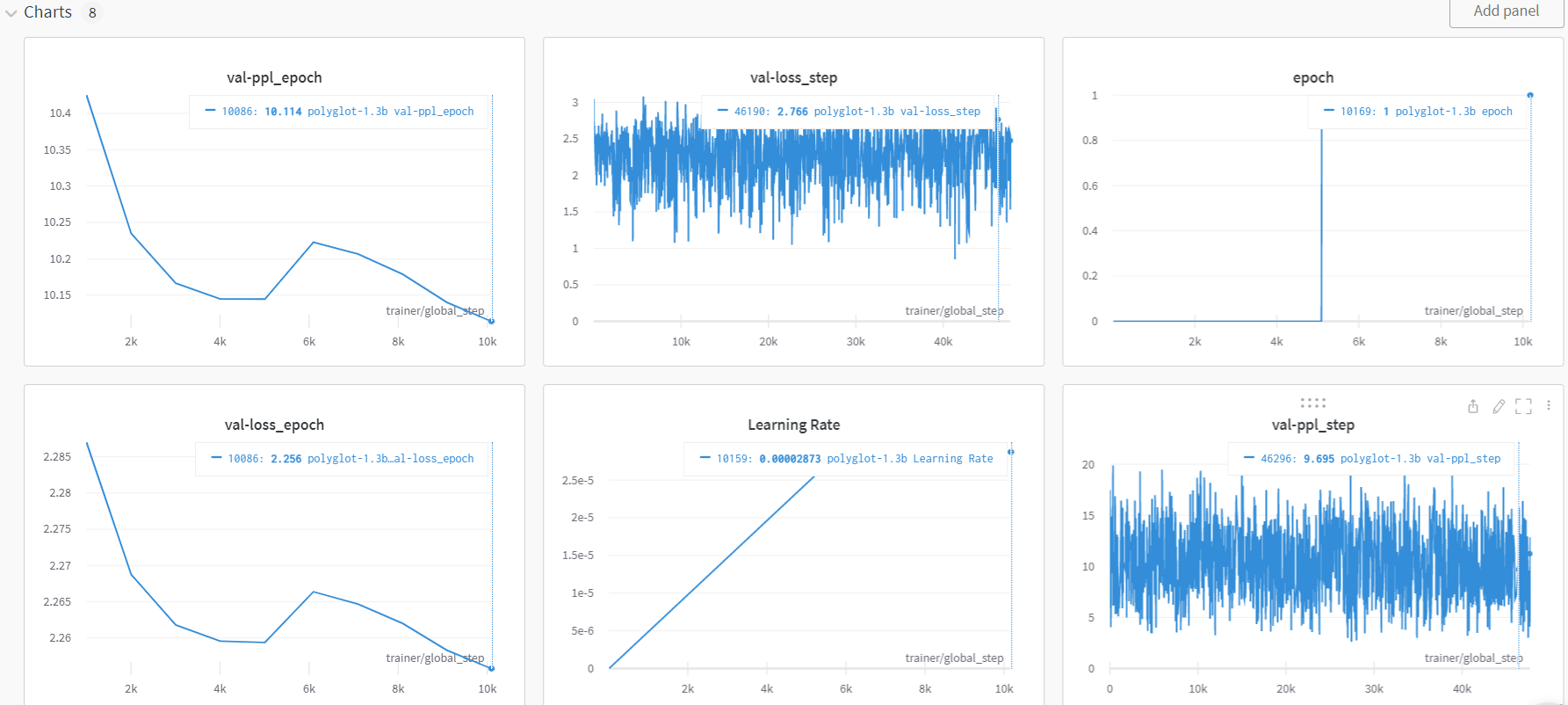
2)와 3)의 경우 2 Epoch 정도를 돌릴 때에 필요했던 시간은 대략 48시간 정도였기에, 서버를 제공 받기 전에 어떤 모델을 사용할지 선택해야 했습니다. 1)의 경우 이미 규모적인 측면이나 생성된 결과를 보았을 때, 확연히 성능이 좋지 않다는 결론을 내렸기에 일찌감치 제외시켰고, 남은 두 모델에 대해서만 고려했습니다.
이 때 생성된 결과물에 대해 발견할 수 있었던 문제점은 다음과 같았습니다.
- 생성되는 문장의 말투가 반말과 존댓말을 오간다. -> 사람의 개입으로 수정
- 학습 step이 충분하지 않을 수록 사전 학습 때 사용된 데이터가 나왔다.(학습 데이터로 넣지 않은 블로그 글이나 이모티콘, 인스타그램 태그 등) -> step을 늘리자.
- 특정 길이 이상을 넘어갈 때 모델이 이상한 결과를 생성한다. -> 필요한 부분까지만 잘라서 이용하자.
- 2만자라는 긴 글을 생성할 때 맥락은 어떻게 유지할 수 있지? -> d. 팀 전략
d. 팀 전략
저희 팀은 특히 '어떻게 2만자 동안 일관된 내용을 생성할 수 있을까?'에 대해 생각해보았습니다. 최종적으로는 다른 팀들도 다양한 전략을 가지고 나와 결과물을 발표하셨는데, 그 중에는 저희가 이전에 논의한 내용들도 있어 흥미로웠습니다. 이번 대회의 경우, '사람의 개입'이 어느정도까지 가능한지에 대한 규정이 본선 당일에야 확정이 되어서 그 부분에 대해 심사가 어떤 식으로 진행될지 감을 잡기 어려웠습니다. 그래서 글 생성 전략도 팀별로도 많이 다양했던 것 같습니다.
크게 소제목을 미리 정하였느냐, 아니었냐의 기준으로 방법을 나눌 수 있을 것 같습니다.
소제목으로 미리 글의 개요를 정하고 글을 작성한 팀이 많았는데, 소제목을 사용하는 방법도 여러 가지였습니다. 미리 소제목을 나눠서 학습해온 팀도 있었고, 유사도를 기준으로 하여 관련된 내용을 찾아서 데이터를 추가 학습한 팀도 있었습니다. 저희 팀의 경우는 처음부터 소제목을 사용할 생각은 아니었지만, 글의 구성상 소제목을 사용해야겠다는 판단을 하여 사용하였습니다.(자세한 내용은 뒤에서 이어집니다.)
소제목을 미리 사용하지 않은 팀들은 AI 모델에게 글의 생성을 완전히 맡기거나, 사람이 그때그때 개입하여 인풋으로 내용과 관련된 어절이나 문장을 제시하는 방식이었습니다.(이 방식의 경우 대부분의 팀이 사용하였습니다.) 혹은 슬라이딩 윈도우를 도입하거나, KR-WordRank를 사용해 앞 내용의 키워드를 추출하여 이를 인풋과 함께 넣어주는 방식도 있었습니다.
저희 팀은 문맥을 유지하기 위한 여러 가지 전략을 생각해보다가, 인풋을 넣어줄 때 '모델이 생성한 마지막 문장을 다시 인풋으로 넣을까? -> 모델이 생성한 여러 문장을 인풋으로 넣을까? -> 모델이 생성한 여러 문장과 사람이 넣는 단어를 인풋으로 넣을까? -> 요약문과 제목을 인풋으로 넣자!'의 흐름으로 발전하여 최종적으로 요약문을 사용하는 방법을 생각했습니다.

즉, 생성 모델에 더하여 요약 모델까지 이용함으로써 2만자라는 긴 분량에도 맥락을 효과적으로 유지할 수 있었습니다.
구체적으로는 사람이 인풋으로 주는 것은 '제목'뿐이었고, 이 제목을 보고 모델은 계속해서 "글을 생성-> 요약문 생성 -> 요약문을 제목과 함께 생성 모델의 인풋으로 넣기 -> 글을 생성"의 과정을 반복하며 글을 생성해냈습니다. 이 과정이 가능하게 하기 위해서, 저희는 json 형식의 데이터를 활용하여 제목과 내용을 구분할 수 있게 데이터를 정리하였습니다. 또한, 학습을 진행할 때 "요약:~~ \n 제목:~~~ \n 내용"의 형식으로 학습데이터를 구성하여 학습을 진행했습니다.
4. 본선
약 2주간의 준비 기간이 끝난 후에 본격적으로 무박 2일간의 여정이 시작되었을 때, 저희 팀은 미리 학습되어 있던 '요약문을 학습한 생성모델'을 통해 주제어 "담대한"에 어울리는 글을 각자 생성해보았습니다. 사람이 제목을 정해서 입력하면 거기에 대한 내용이 알아서 생성되고, 사람은 어디까지 내용을 사용할 것인지 인덱스를 입력하면, 그 부분까지 다시 요약문을 생성하여 제목과 함께 인풋으로 들어가는 방식으로 진행했습니다. 2만자의 글을 생성하는데 약 1-2시간이 소요되었고, 생각보다 시간이 부족하다고 느꼈습니다.
제가 처음 생성했던 글은 "담대한 도전은 위대하다"라는 주제로 쓴 글이었는데, 이 글을 생성해보면서 요약문을 활용하면 2만자 동안 맥락을 유지하는 게 충분히 가능하구나!라는 것을 실감할 수 있었습니다.
"도전할 때는 담대한 정신이 필요하다고 한다. ... 나는 위대한 도전을 위해 매일 “나에게 위대한 도전은 무엇인가?”라는 물음과 함께 나의 생각들을 정리한다. 내가 생각해낼 수 있고, 해낼 수 있는 모든 것들을 하나하나 끄집어내서 그것들이 내 삶에 어떠한 긍정적인 의미와 영향을 줄 수 있는지에 대해 고민하고 판단한다. 그렇게 나만의 기준으로 선택된 위대한 도전을 할 때에 그것들은 나의 삶에 어떤 의미를 줄 수 있는지 다시금 되새기며 더욱 견고해지려 노력한다. 그리고 이 과정 속에서 나를 더욱 성장시킬 수 있게 된다." - AI WRITER

이와 비슷하게 각 팀원들이 돌아가면서 글을 생성해보며 약 5-6편의 글을 일단 확보하였는데, 이 때 글을 프린트하여 읽어보면서 느낀 점은 글이 단조롭다, 라는 것이었습니다. 왜냐하면 글에서 계속해서 주요 주제에 대한 내용은 반복되고 있지만, 사실상 비슷한 말을 비슷하게 반복하는 형상이었기 때문에 이대로면 의미없이 글만 늘려쓴 게 될 수도 있겠다라고 생각했습니다.
따라서 이 부분을 어떻게 극복할까 논의하던 중에, 이미 생성해 놓은 글들을 조합하여 하나의 글로 엮자는 아이디어를 떠올렸습니다. 이 때, 저희 팀은 사람의 개입이 어느정도까지 가능한지 제대로 파악하지 못했기에 최대한 소제목을 많이 나누지 않는 편으로 전략을 세웠습니다.(그렇지만 지금 돌이켜보면 소제목을 많이 나누고, 사람의 개입이 꽤나 들어가는 한이 있더라도 작품이 쉽게 읽히고 눈에 잘 들어오는 내용이 더 유리했던 것 같다는 생각이 듭니다.)
그래서 최종적으로 정해진 글의 제목은 "죽음, 담대하게 마주하다"였습니다. 글의 흥미를 돋우기 위해 '어두움->밝음'의 테마로 글을 전개시키기로 생각했고, 따라서 앞 부분은 '어두운, 불안한, 겁먹은' 느낌의 글을, 뒤로 갈 수록 '그럼에도 의미가 있기에 이젠 괜찮다.'의 내용으로 글을 구성하였습니다.
그래서 최종 완성된 글의 핵심 문장은 다음과 같았습니다. 전체 작품은 이 곳에서 확인하실 수 있습니다.

5. 느낀 점
a. 대회 전반적인 느낀점
이러한 노력의 과정이 있었으나 아쉽게도 수상은 하지 못했습니다. 물론 다른 팀들의 결과물을 살펴보지 못해 단언할 수는 없으나, 개인적으로 느낀 점을 조금 남겨두려 합니다.(내년 대회에 이 부분들을 보완해서 참여하기 위해서) 이번 대회에서는 AI 활용성 뿐만 아니라, 문학적인 측면에서 어떤 내용을 가독성 좋게 전하고 있는지가 꽤나 중요한 요소로 작용하는 듯 해보였습니다.
- 가독성을 위해 소제목을 넣거나,
- 짧은 심사시간에도 한번에 읽힐 수 있는 가독성 좋은 글
또한, 생각보다 사람의 개입이나 글의 분량을 엄격하게 제한하지 않아서, 사람의 개입이 많이 들어가더라도 원하는 플롯을 짜두고 수필을 전개하는 편이 좋은 결과를 얻기에 더 유리했던 것 같습니다. 그리고 굳이 2만자를 채우려고 하기 보다는 차라리 분량이 부족하더라도 이야기가 잘 읽히도록 하는 편이 더 좋은 평가를 받을 수 있었다는 생각이 들었습니다. 또한, 그렇기 때문에 많은 팀들이 고민했음에도 불구하고 2만자를 모델이 끝까지 맥락을 유지해서 생성하는 부분은 딱히 영향력을 발휘하지 못했던 것 같습니다.
무박 2일동안 글을 생성하는 과정은(그리고 2만자 가량의 글을 여러 편 읽는 과정은) 꽤나 많은 집중력을 요구하는 작업이었습니다. 밤을 새는 것 또한 그 이유였을 수 있지만, 생성과 요약, 그리고 사람이 아웃풋을 선택하는 과정을 자동화하는 방식으로 2만자의 글을 작성하도록 편리하게 구성했음에도 불구하고 하나의 글을 완성하기까지는 꽤나 시간이 필요했기에 실제로 주어진 약 하루동안의 시간이 결코 충분한 편이 아니었습니다. 그래서 더 다양한 내용의 글을 생각해보고 검토해보지 못한 것이 아쉬웠습니다.
또한, 심사기준이 계속 바뀌어서 혼선이 있었던 점도 아쉬움으로 남았습니다. 인간의 개입이 어느정도까지 가능할 것인가의 측면에서 대회 당일까지 규정이 수정되기도 하였고, 어떤 식의 접근이 심사기준을 충족할 수 있는지 파악하기 어려웠던 것도 그러했습니다.(인간의 개입을 통해 문맥을 정리할 수 있는 것인지 등의 접근에서)
b. 스스로의 성장
이번 대회를 통해 느끼고 배운 점도 많았습니다. 다른 팀들의 발표를 보면서 저렇게 많고 다양한 방법들로 글을 생성할 수 있구나,라는 것을 느꼈습니다. 그 과정에서도 여러모로 색다른 방법들에 감탄도 했고, 다른 프로젝트를 진행할 때 참고하면 좋을만한 것들을 메모해 두기도 했습니다.
그리고 본선에서 다양한 팀들을 만나기 이전에도 이미 함께 본선을 준비하면서 팀 내에서도 많은 것을 배울 수 있었습니다.
이번 대회를 통해 처음 만난 팀원분이지만, 해야하는 일들이 척척 해결되어 코드로 만들어질 때 정말이지 놀라움과 존경심이 들 정도였습니다. 팀원분들께서 본선 대회를 진행하면서도 피곤함을 누르며 준비해야 하는 것들을 끝까지 해나가는 모습을 보면서 더 열심히 해야지라는 생각을 절로 했던 것 같습니다. 개인적으로 이 대회에서 생각지도 못한 많은 것을 얻어갈 수 있어 더없이 만족스럽다는 생각이 들 정도로, 스스로 동기부여도 되고 성장도 이뤄낼 수 있었던 경험이었습니다.
특히 사소하다고 생각할 수 있는 부분들에서도 앞으로 제가 적용하면 좋을 부분들이 많았는데,
- 깃허브 commit message 신경쓰기
- wandb 활용하기
- 허깅페이스에 모델 push해서 관리 및 사용하기
- CLI에서 명령어를 줄 수 있도록 코드 구현하기(특히 모델 학습과 같은 반복적인 task에서는 jupyter notebook 사용 지양하기)
- 사소한 부분일지라도 한 줄이라도 코드에 대한 README 작성하기
- 데이터를 json 형식으로 수집하기
와 같은 부분들이었습니다. 이외에도 정말 이 대회 참여 못했으면, 이 팀으로 못 만났으면 어떡할 뻔했지?라는 생각이 절로 들 정도로 저에게는 행운과 같은 나날들이었고 약 3주 간의 긴 여정 동안 수고한 팀원분들께 진심으로 감사하다는 말을 전해드리고 싶습니다.
+) 그리고 또다시 느낀 점이 있다면, 이 대회를 준비하면서 그리고 본선에 임하면서 '재밌다, 즐겁다'라는 감정을 느꼈던 점이었습니다. 제가 가고자 하는 길, 그리고 제가 하고 싶어 했던 task를 할 때, 사실 그 모든 것이 제 꿈을 향하는 과정이었고 그를 위해 배울 수 있는 시간이자 경험이었기에, 힘들다는 기분이 든 적이 한 번도(밤을 샐 때를 제외하고는..) 없었던 것 같다는 것이 신기했습니다. 제가 좋아하는 것들이 모여 있었기에 더욱 그랬던 것일지도 모르겠네요. 앞으로도 이런 소중한 기회가 찾아올 수 있도록 열심히 준비해야 겠습니다.
'✨ 포트폴리오 > 2023' 카테고리의 다른 글
| [대회] 노트북으로 GPT 맛보기 : 생성 요약 (Abstractive Summary) 대회 (0) | 2023.03.30 |
|---|---|
| [프로젝트] chatgpt-story-maker : chatgpt api를 이용한 이야기 제작 (0) | 2023.03.05 |
| [장학] 2023 관정이종환장학재단 학부장학생 면접/최종 합격 후기 (0) | 2023.02.11 |