데이터 분석 큰 그림 흐름
1. problem definition
2. solution
3. conclusion
데이터 분석 과정
데이터 준비
- 데이터 준비 큰 흐름
: 데이터 적절하게 수집
-> 데이터 프로파일링(데이터가 어떤 형태인지, 한 번 쭉 보면서 이해)
-> 이상한 값, 빠진 값 들을 정제
-> 데이터를 분석할 수 있는 형태로 재구조화
-> 모델 만들기
Data Preparation
1. Exploratory Data Analysis(EDA)
1) 도메인 지식 기반 데이터 탐색
: 전체적으로 탐색한다. 이 데이터는 어디서 왔고, 무엇에 대한 데이터인지
2) 속성 탐색
: 컬럼의 의미와, 각 특징들
3) 패턴 탐색
: 데이터의 전체적인 패턴을 파악(예. 시간의 흐름에 따라 패턴이 있나?)
2. Data pre-processing
1) 결측치 처리
2) 아웃라이어 처리
+) anomaly 값 처리
Data Preparation - 1. Exploratory Data Analysis(EDA)
데이터를 분석 -> 특징을 요약.
1-1) Comprehensive Data Exploration
- 도메인 지식의 중요성
도메인지식이 매우 중요하다. 도메인 지식이 없다면 데이터 파악도 어렵고, 전처리하는 것도 어렵다. 분석 결과가 나와도 해석하는 것도 어렵다. 그래서 도메인 지식을 갖추는데 많은 시간을 들여야 한다.
- 도메인 지식이 있다면?
그 도메인 지식을 바탕으로,
데이터의 크기, 속성들, 어떤 속성이 얼마나 중요하고, 뭐가 필요없고, 어떤 타입인지 결측값은 있는지(.info()), 전체 통계(.describe())를 전체적인 관점에서 훑어봐야 한다.
1-2) Exploring Attributes
그 다음에 각 속성을 봐야 한다.
- Data Visualization
: 차트나 그래프로 시각화
- Descriptive Statistics
: 통계적인 특성을 확인 - 평균, 최빈값, 중앙값, 분산, 표준편차, 분포 등
- 분산 구할때, 모집단과 표준편차의 식이 다르다

: 표본 집단의 분산을 구할때는 앞의 분모에 n-1이 들어가는데, 그 이유는 평균을 구할때는 상관이 없지만, 분산을 구할때는 모집단에 비해 샘플에서는 과소추정되는 경향이 있어서 이걸 보정하기 위함이다.
1-3) Exploring Patterns
그럼 지금까지 도메인 지식 갖추고, 속성 파악했으면, 이제는 전체적인 패턴이 있는지도 봐야 한다.
-> 데이터 간의 관계 같은 것.
- Covariance(공분산)
두 개의 변수가 같이 변하는 정도를 의미. 하나 증가하면 다른 것도 얼마나 증가하는 가. 같이 어떻게 분산이 커지는가를 측정한다.
여기서도 샘플일 경우에는 분모에 n-1이 들어간다.

- Correlation(상관관계)
상관계수를 두 변수 간의 선형 관계를 나타내준다.
-> 값의 범위가 -1부터 1까지로 정해져 있음.(공분산에 루트(각각의 분산 곱한 값) 나눠줘서 정규화한 값

: 0이면 아무 관련이 없다는 것. -1이면 음의 강한 상관관계가 있다는 것.
- Regularity(규칙성)
데이터셋 안에서 흐름을 봐야 한다. 혹은 anomaly한 값이 있을 수 있는지도 확인(예. 편의점 발주를 평상시 보다 너무 많이 넣음)
Data Preparation - 2. Data Pre-processing
데이터 전처리는 분석을 준비하는데에 매우 중요함. 크게 두 가지가 있다. -> 결측값 처리, 아웃라이어 처리, (이상치 처리)
2-1) Missing Data Processing
- 결측값의 type
1) 완전 랜덤하게 발생 -> MCAR
: 일종의 버그 같은 것. 예) 설문을 보냈는데 체크안한 문항
2) 여전히 랜덤(예측 불가)하긴 하지만 다른 것과 연관이 있긴 함(영향을 받음) -> MAR
: 예) 몸무게 결측이 있다. 근데 성별에 따라 결측이 생긴 경우. / GPS 값이 결측인데, gps 유무를 보니까 없다고 되어 있어서 결측이 생긴 경우.
3) 이유가 있는 결측(랜덤X) -> MNAR
: 일부로 결측을 발생시킨 것. 예) 학점 기입 하기 싫어
- 결측값(Missing data)은 어떻게 찾을까?
: 통계를 확인하거나 시각화.
- 결측값은 어떻게 처리할까(Strategies for dealing with missing data)
1) Retention 그냥 둔다
: 결측값 자체가 좋은 인사이트가 될 수 있을 때(예. 시스템 에러를 발견할 수 ㅇ). 혹은 결측값이 있어야 하는 경우(예. 한국인 미들네임) 혹은 알고리즘이 결측값을 알아서 처리하는 경우(XGBoost나 LightGBM 같은)
2) Deletion 지운다
: 의사결정 빨리 내려야 하는데 결과에 큰 변화가 없다면 그냥 지우는게 더 낫다.
행을 날릴지, 열을 날릴지는 도메인 지식으로 판단해야 한다.(예) 설문조사 결측값 있는 행? 지운다. / 결측값 너무 많고 컬럼 의미가 모호하다? 지운다)
dataframe.dropna()
del dataframe['col'] : 열을 지울 때
3) Imputation 바꾼다
가만히 놔둘 수도 지울 수도 없다면, 어떻게든 채워야 한다. 추측을 해서 채운다.
- Cold Deck Imputation
: 외부의 지식을 바탕으로 넣는다. 값을 채워야 하는데 근거를 가져오기 힘들때(다른 컬럼을 봐도 모르겠음) 혹은 내가 값을 채울 수 있을때(예. 아기의 결혼 여부.)
- Hot Deck Imputation
: 데이터 안에서 가장 비슷한 애의 데이터 혹은 관련된 데이터를 끼운다.
-- distribution-based
: 평균, 중앙, 최빈값
-- forward fill / backward fill / linear interpolation
: 시계열 데이터 일때
-- KNN이나 regression과 같은 예측 알고리즘 사용

다른 컬럼의 평균/중앙/최빈값을 가져와서 결측에 채워넣을 수도 있음.
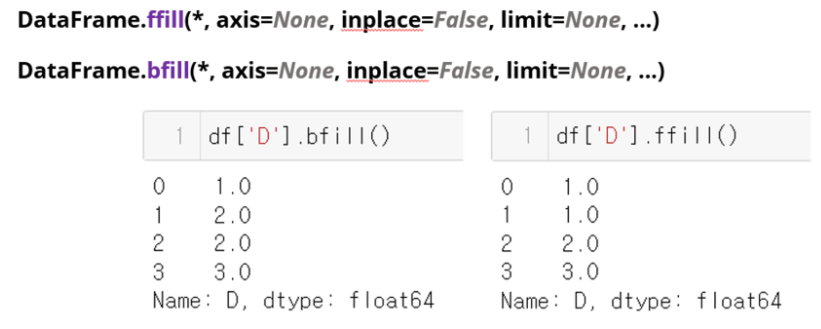
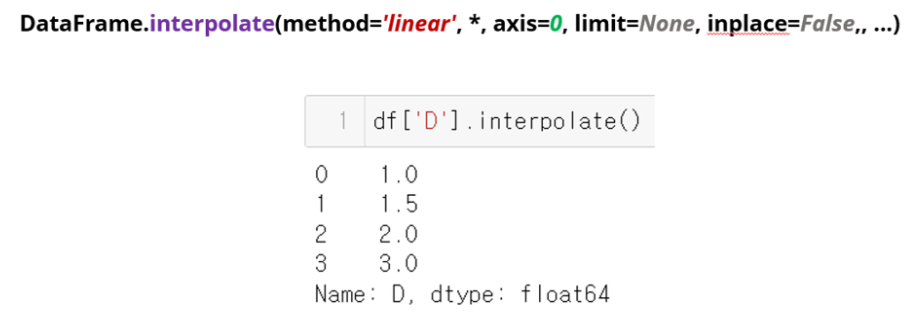
ffill, bfill, interpolate도 이런 식으로 하면 됨.
2-2) Outlier Processing
데이터가 분포와 너무 다른 값을 가질 때 outlier라고 부른다. - 판단 하는 기준도 정답은 없다.
- Outlier의 타입
1) global outlier
: 전체 데이터셋의 다른 데이터들과 너무 다를때.
예) 키가 2m 20cm.
2) contextual outlier
: 특정 context나 subset에서만 outlier일때.
- Outlier Processing
어떻게 아웃라이어인지 아닌지를 판단할까?
1) 도메인 지식을 활용한다.
2) 통계적 방법
-- Z-score
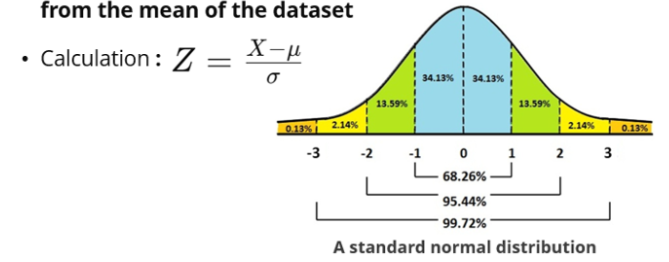
평균에서 얼마나 떨어져 있는 지를 알 수 있다. 표준화 하는 공식으로 z 값을 구함.(평균 빼고 분산으로 나누고)
값이 0이라는건 평균이랑 값이 같다는 의미이고, 0보다 크면 x는 평균보다 크다는 의미임.
-> 보통 z-score가 2나 3 표준편차보다 크면 outlier로 생각함.
-- IQR
백분위수를 구해야 한다. 25% 그리고 75%인 데이터에 따라 나눌 것이다.
-> 가장 먼저 정렬을 하고, 25%(Q1)와 75%(Q3)를 구할 거라면, 그 비율에 총 데이터수를 곱해서 몇 번째에 해당하는 데이터가 해당 데이터인지를 찾는다.
(예. 데이터가 6개였다면, 0.25*6=1.5 -> 1.5번째 데이터가 25%에 해당하는 데이터이다)
근데 등수가 소수점 뒤로 값을 가진다면, 사이의 값은 당연히도 이렇게 구한다.
=> 구하고 싶은 값 = 작은값 + 소수부분*(큰값-작은값)
그래서 Q3-Q1 - IQR이라고 부른다. 여기서 각 Q1과 Q3에서 1.5 IQR 넘게 떨어진 값을 아웃라이어로 부르겠다는 것.(Q1-1.5*IQR보다 작거나, Q3+1.5*IQR보다 크거나)
pandas로 구현하면 이 계산법과 조금 다른 결과가 나오는데, 그건 값을 보정해줬기 때문이다.(25%와 75%에 데이터갯수 곱할때 -1을 해서 곱하고, 그 후에 랭킹 값을 1을 더해준다.
3) 알고리즘을 활용
결정트리와 랜덤포레스트를 활용할 수도 있다. 아웃라이어는 결국 다른 데이터들과 떨어져 있다는 것 -> 결정트리 분기할 때 아웃라이어는 떨어뜨리기 쉽겠네 하는 것이 => isolation forest이다.
- 아웃라이어는 어떻게 처리할까?(Strategies for dealing with outliers)
1) Retention 그냥 둔다
: 아웃라이어가 의미있는 정보를 담고 있을때(예. 심장병 진단 - 심장박동수)
내가 하고자 하는 거랑 너무 관계가 크면 건들면 안된다.(예. 사기 탐지)
2) Deletion 지운다
: 에러로 인해 잘못 찍힌 값들은 지운다. 그리고 샘플링이 잘못되어 데이터가 수집되었을 때(예. 평균 독서량 - 근데 서점 주인 데이터가 있으면)
3) Imputation 값을 고친다
아웃라이어를 없앨수는 없는데 조정을 해야 한다면, 극단치를 조정하거나(예. 1,2,3,999였다면 999를 데이터에서 가장 가까운 값으로 바꿔준다. -> 1,2,3,3 / 혹은 더 큰 값들을 상위 5%정도로 맞춘다거나) 로그 변환을 한다.
로그로 변환하면 선형적으로 데이터를 바꿔준다.
*** outlier 처리에서 중요한 부분
만약 키 120에서 몸무게 20kg가 이상치인가? 라는 생각으로 그냥 컬럼 별로 (무지성) IQR을 돌린다면 이상값 처리가 될 수도 있다. 하지만 키랑 같이 고려하면 정상적인 값!
2-3) Anomaly Processing
anomaly는 말이 안되는 "잘못된" 값이라는 것이다.(예. 키 300cm, 학점 4.6)
- anomaly는 어떻게 처리할까?
1) 지운다
: 하지만 anomaly가 왜 생겼는지 모른다면 지워야한다.
2) 고친다
: 이것도 왜 생겼는지 이유를 알아야 한다. 하지만 도메인 지식이 필요하다.
여기선 그냥 둔다의 옵션은 없다.